


The world has become increasingly digital and a very high volume of data is being generated and consumed of late. It is therefore important that the data owners are able to identify whether the dataset they have is a High Value Dataset (HVD) or not. This blog is therefore an attempt to provide a template for distinguishing an HVD.
The Definition:
The datasets which could be instrumental in deriving important benefits for the society, the environment and the economy, in particular, because of their ability towards creating value- added services for efficiency and convenience by making the best use of AI/ML technologies are considered as High-Value datasets.
A High Value Dataset should be able to meet either of the following characteristics:
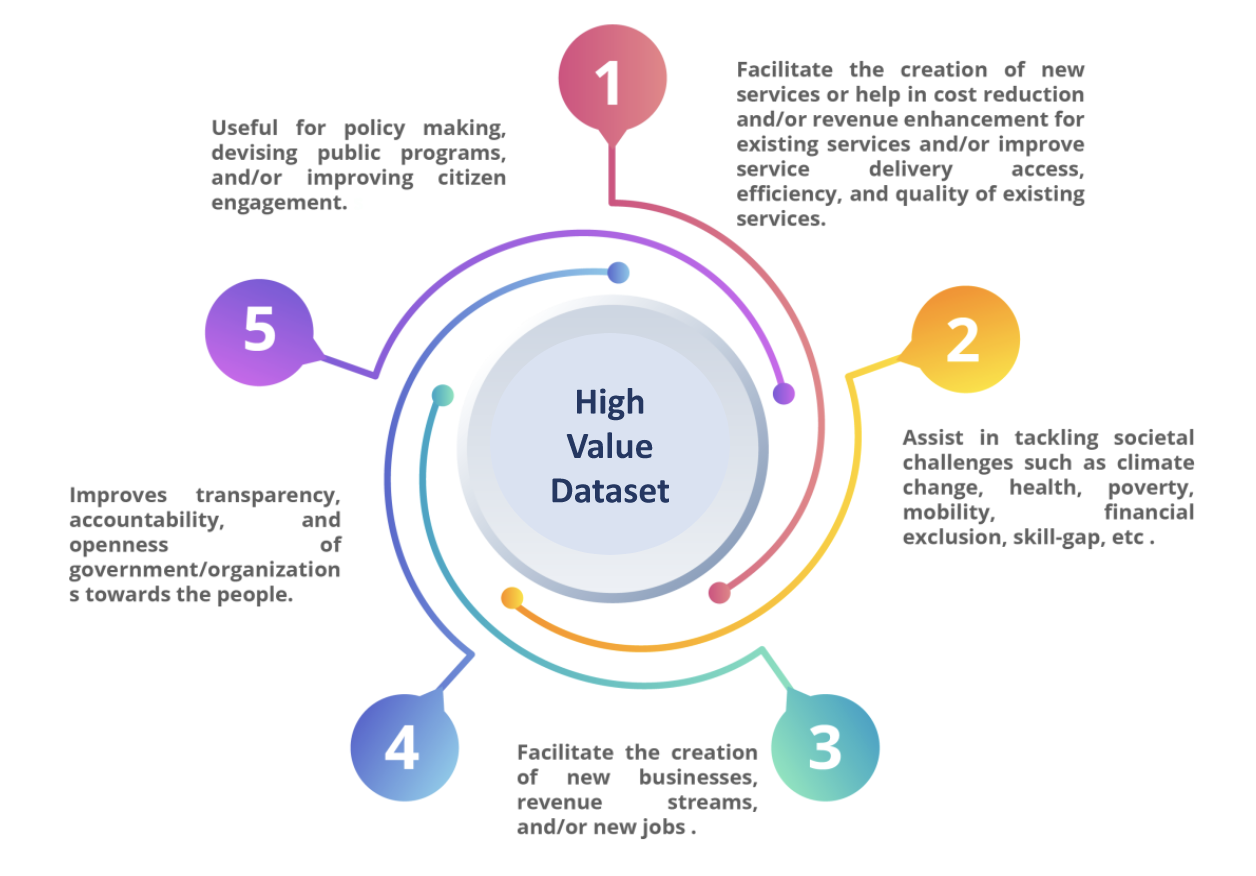
Example High Value Datasets:
As of December 2022, IUDX has worked with over 30 Smart cities to onboard 225+ HVDs across various domains within Urban Governance. Some of the example HVDs onboarded by IUDX for the Mobility domain along with the value it can create is as given below:
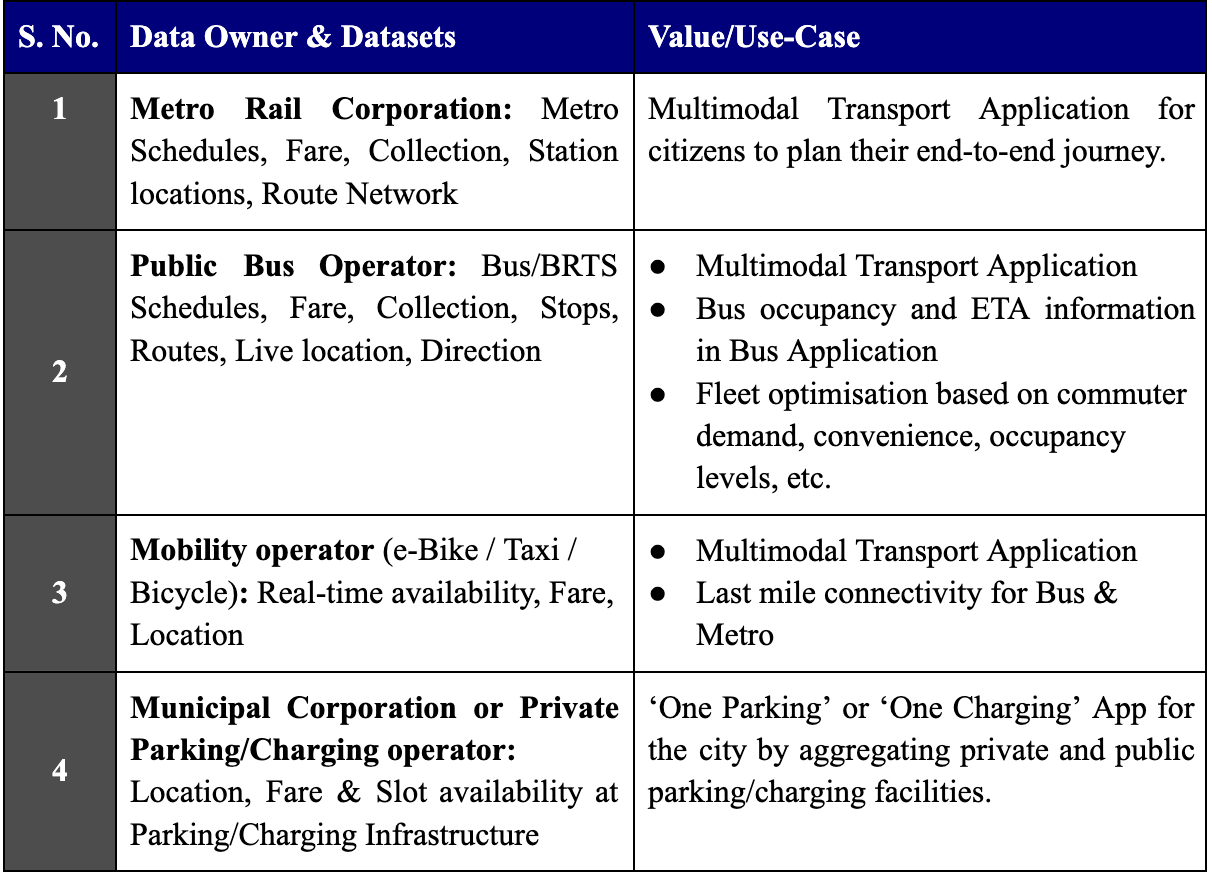
Once a dataset is ascertained to be an HVD, the data owner should then work towards assessing its quality, its value and eventually identify the ways to monetize it and/or utilize it for creating value for society, environment, or economy. In the next blog on HVDs, we will cover some of the data valuation frameworks being used across industries and some data monetization techniques.
It’s time for the public/private organizations to start working on identifying HVDs in their domain & eventually work towards maximizing its potential by building an application/solution over it and/or monetizing it.
Names of the author:
Akshat Sharma
Related Posts





























{kind=link}