


In the previous post, we explored the reasons that a Data Quality Assessment (DQA) framework is important for a data exchange platform such as IUDX. We looked at how such a DQA framework/tool would be modularly designed and positioned in the existing IUDX architecture, and the benefits to both upstream and downstream stakeholders. In this post, we will discuss the framework in the context of a data exchange platform.
On what basis can data quality be judged? This question becomes especially pertinent when one considers the relevance of different aspects or features of data vis-à-vis different application domains. As an example, the WHO may collect data about the number of positive cases of a certain virus, and their primary focus would be on the count, gender, demographic, etc of the patients. They would not necessarily be as concerned with the timeliness of the data as long as it falls within certain acceptable bounds. However, for a time critical application such as ambulance location data, the timeliness of the data becomes one of the primary data quality parameters. These different features of data quality, such as timeliness or outliers, are classified as different data quality dimensions in the existing literature.
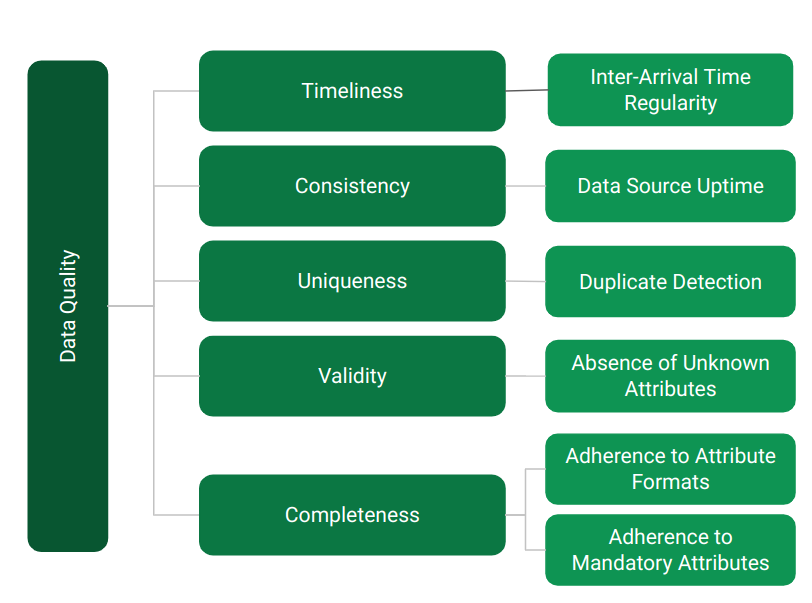
One of the primary types of data hosted on IUDX is of a temporal nature, i.e. data where every data packet is accompanied by a timestamp. This includes, but is not limited to, data collected from sensors, data from vehicle trackers, etc. Thus, our primary focus is on evaluating data quality for such temporal datasets. The data quality metrics that we choose for this evaluation must remain domain agnostic, since that will generalise applicability of the assessment framework to all temporal data sources irrespective of the application domain. With this context, the five DQ dimensions that are mentioned below, are relevant for our analysis. These five dimensions, which can be applied and tailored for the widest variety of use-cases, are:
- 1. Timeliness
- 2. Consistency
- 3. Uniqueness
- 4. Validity
- 5. Completeness
These dimensions provide a reference point for us to further define quantifiable metrics applicable to the class of temporal datasets available on IUDX. We want to refine these metrics in such a way that each one of these is normalizable to a quantity between 0 and 1, with 1 representing the highest quality. The timeliness of data packets is of particular importance for temporal data. It is also important to understand if the data packets are missing any important data attributes or whether the packets contain undefined data attributes. Other important parameters that we want to measure are whether the data adheres to the specified data formats and structure, and the presence of duplicate data. Thus, we arrive at the following data quality metrics that form the basis of our Data Quality Assessment framework:
- 1. Inter-Arrival Time Regularity: This metric conveys how uniform the time interval is between the receipt of two consecutive packets.
- 2. Data Source Uptime: This metric evaluates whether the data is actively received. An outage of reception may possibly point to an anomalous event, such as device downtime, etc.
- 3. Duplicate Detection: This metric evaluates the percentage of duplicate data packets that are present in the dataset.
- 4. Absence of Unknown Attributes: This metric checks whether there are any additional attributes present in the dataset apart from the list of required attributes defined in the schema.
- 5. Adherence to Attribute Formats: This metric assesses the adherence of the data to its expected format as defined in the data schema.
- 6. Adherence to Mandatory Attributes: This metric checks whether all the required attributes defined in the schema are present in the dataset.
Fig.1: The Data Quality Metrics
These metrics serve to cover the majority of the quantifiable attributes that are associated with temporal data. At IUDX we are working to provide the user with metrics to measure data quality so that one can make an informed choice while developing applications. This also enables the data provider to receive feedback on the quality of data being generated by their systems and take necessary remedial actions if needed. To make this process more accessible for the end-user, IUDX has developed a tool that generates PDF reports that delineate the quality of a dataset based on the metrics defined above. We are also working to integrate the data quality reporting within the IUDX catalogue. In the future, data quality could be offered as a service, which means that an exchange consumer could request data quality assessment on demand.
More links:
Link to Part 1 of the Data Quality Series
Github Repository for IUDX Data Quality Assessment Tool
Sample Data Quality PDF Report
Names of the authors:
Novoneel Chakraborty, YLT Fellow – IUDX Program Unit, IISc
Jyotirmoy Dutta, Specialist Scientist – Centre for Society and Policy, IISc
Related Posts




























{kind=link}