


Many of the keystone applications running a “smart” city will require data sharing between parties with heterogenous interests. As an example, let’s imagine an “intelligent” transport management system (ITMS) that might optimise end-to-end transit times, measure and mitigate air pollution, manage city-wide transport carbon emissions, minimize traffic congestion and signal waiting times, support planning and building new infrastructure, etc. This system would use data – regarding trip origins and destinations, estimated arrival times, traffic densities, currently ongoing roadworks, air pollution etc – shared between individuals, cab aggregators, last mile transport providers, public bus transport, city planners, etc.
Privacy aspects emerge as soon as data is to be shared. While it is possible to anonymise data before release to another party (or the public), how can we ensure that downstream analyses, especially leveraging powerful machine learning and computational ability, cannot be used to compromise the privacy of individuals and businesses? Privacy concerns also arise in the context of data that is “held” (and not shared) by companies. Breaches of such data expose businesses to liability and risk when they violate the confidentiality of individuals – even if they are held in “anonymised” format.
“Differential Privacy” (DP), considered by some to be the “gold standard” for privacy, addresses these types of issues. It is a framework that allows for datasets and analyses to be released in a manner that preserves individual privacy in a quantified way, within a “budget”. This is through the addition of controlled “noise” to the data or analysis before release. Noise is usually the bane of information systems – consider the unpleasantness of interference in a telephone call! – but in DP is harnessed for a useful purpose – namely, to mask the identity of the individuals who were involved in the creation of the dataset.
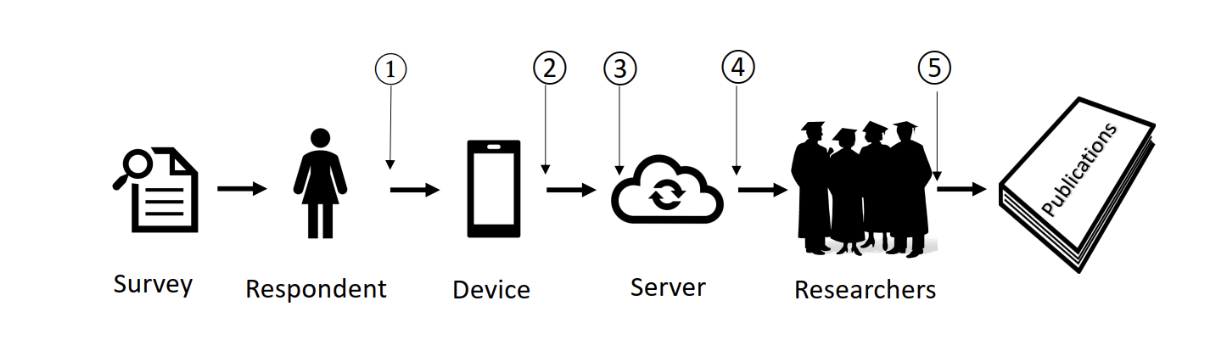
This “noise” can be added at various points in the process of creating and processing of data, as illustrated in the figure above depicting a citizen survey. Let’s say that the survey in question is for a research study regarding driving habits. There may be a question asking if a particular respondent has ever violated a red-light signal. Some respondents might have issues with this fact about them being known, and might be concerned about revealing potentially incriminating information. The challenge then is – how do we collect this information, say towards researching and developing better traffic management outcomes – while assuring respondents that their privacy will be protected? “Randomized response” (RR) is a technique by which the “true” response of a survey participant is masked so as to offer them “plausible deniability” if required. While RR has been in use since the 1960s, it can be viewed as a specific instance of a “mechanism” for Differential Privacy. Like all “mechanisms” that implement DP, RR can be performed within a privacy budget, related to the degree to which the true responses are perturbed.
Even when issues of plausible deniability are not important, there can be thorny issues of privacy violation associated with seemingly innocuous data releases. Latanya Sweeney, in her landmark article “Only You, Your Doctor, and Many Others May Know” described how she successfully carried out several “re-identification attacks”, including the identification of medical records of the then-Governor of the US State of Massachusetts. She accomplished this by using a publicly available voter list in combination with a publicly available dataset of medical information about state employees. The medical dataset had been “de-identified” according to the best practices of the time – including removal of names and addresses, etc., but birth date, gender and ZIP (postal) code remained. Sweeney found that the Governor’s demographics were unique in both datasets; she was able to consequently locate his specific medical records despite its de-identification.
It should be emphasised that both datasets utilised for the attack were released and available with legitimate intent. Voters’ lists are commonly released publicly in many jurisdictions in order to aid transparency, allow public scrutiny to correct errors and omissions, etc. Further, the hospital dataset was issued for research purposes by the Massachusetts Group Insurance Commission, and contained patient diagnoses, along with some demographic information. Since the identity of individual patients was not present in the dataset, the publication was considered “harmless”.

In her article Sweeney describes other attacks, including automated approaches combining different sources of readily available information to perform re-identification. Her research was suppressed for a decade in the academic world, for fear of misuse without an appropriate mitigation. Despite this, it was hugely influential in the policy world, and had a direct impact on the US health privacy policy, known as the Health Insurance Portability and Accountability Act of 1996 (HIPAA).
Sweeney herself identifies Differential Privacy, created in 2006 by Cynthia Dwork and her collaborators, as the tool that “guarantees limited re-identification”. As mentioned previously, DP allows for datasets and analyses to be released while mitigating re-identification through the controlled application of noise before the query result is released. The specific “randomization mechanism” used depends on the type of query, the form of the data released (is it the whole table? Is it aggregated statistics? Is it an image? etc) and the intended downstream application(s).
There are many different emerging applications of the framework. The first large-scale application of DP was in the ‘Disclosure Avoidance System’ of the 2020 US Census. The US Census Bureau is obligated by law to protect the confidentiality of individuals and businesses; while the department has a long history of protecting released data through various measures, ensuring a balance between “confidentiality” and “accuracy” of released statistics is seen as a challenging task, especially in a landscape of high-performance computing, big data, AI, and emerging quantum computing technologies.
Big technology firms also apply DP to protect consumer privacy, while allowing them to collect useful information. For example, data such as – which sites are draining cell phone energy, or causing the browser to crash? What are the most commonly used emoji icons by users in their chats? etc – are useful for companies like Apple and Microsoft to improve the product experience for users. The challenge is to collect this data across millions of devices while precluding re-identification even after name and identifier removal, etc. have been applied. Apple uses an approach called “Local Differential Privacy” wherein every participating device “contributes” a part of its “user sketch” within a strict privacy budget. These signals are aggregated into the centralised models and technology that underpin its products. For example, data on word frequencies in typing can be aggregated across users into a machine-learning based model for prediction, etc. Performing this aggregation can provide a smoother user experience contextualised by geography, language etc.
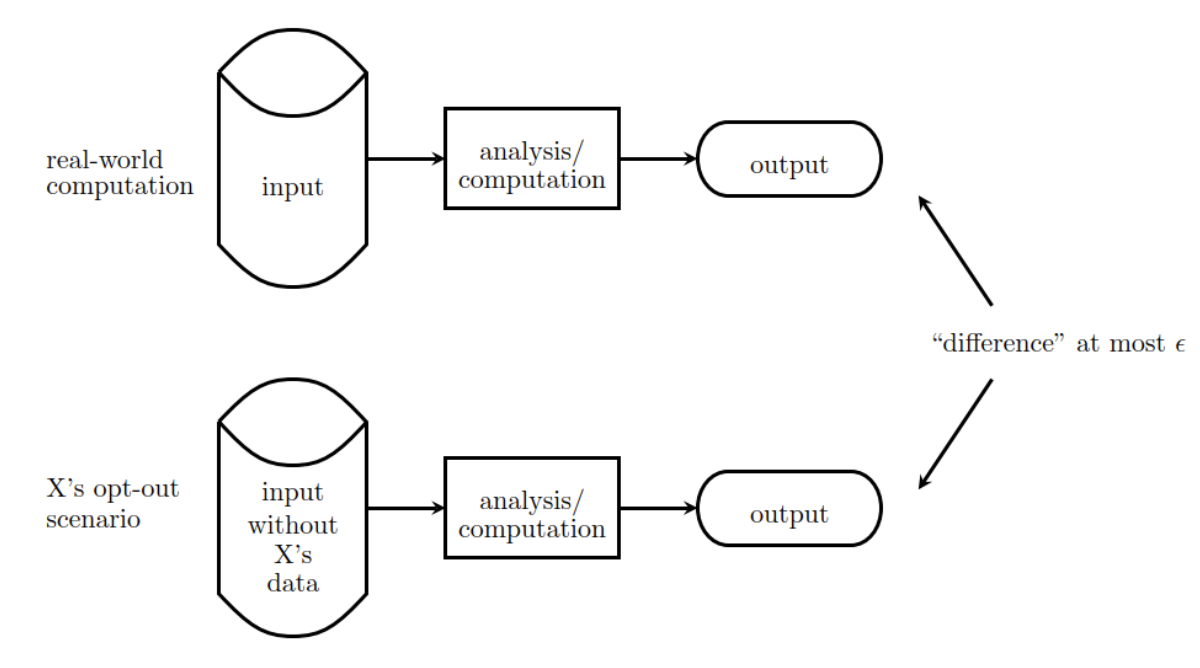
One of the open questions in the field is the appropriate selection of privacy budgets for these types of applications; this budget is represented by “epsilon”. The interpretation of this parameter is also an area of active research. One way is to understand its meaning is to imagine the “maximum difference” in the results of an analysis (e.g. estimating the number of HIV-positive individuals in a population) with and without a particular individual in the input dataset. In this case, as showed in the figure below, epsilon can be thought of as the “privacy loss” we can tolerate for an individual. If the bound holds simultaneously for all the individuals in the dataset, then we can think of the analysis/computation as being differentially private with a budget proportional to epsilon.
The smaller epsilon is, the greater the protection of individual user privacy in released statistics, analyses, images, tables and even trained machine learning models. However, in the privacy world as elsewhere, there is no “free lunch”; there are a number of trade-offs to consider.
For example, the smaller the privacy budget, the more the noise that the randomized mechanism will have to add per sample, and the smaller the overall “utility”, or usefulness, of the released data to a downstream application, in general. Also, for very tight privacy bounds, the “Fundamental Law of Information Recovery” kicks in – “overly accurate answers to too many questions will destroy privacy in a spectacular way”, in the words of the creator of Differential Privacy. This means that a tight privacy budget will be “used up” very quickly with repeated queries. If the downstream application is allowed to perform queries past the allocated budget, then individual privacy will start to be compromised as noise can be estimated accurately enough to reveal the true query results.
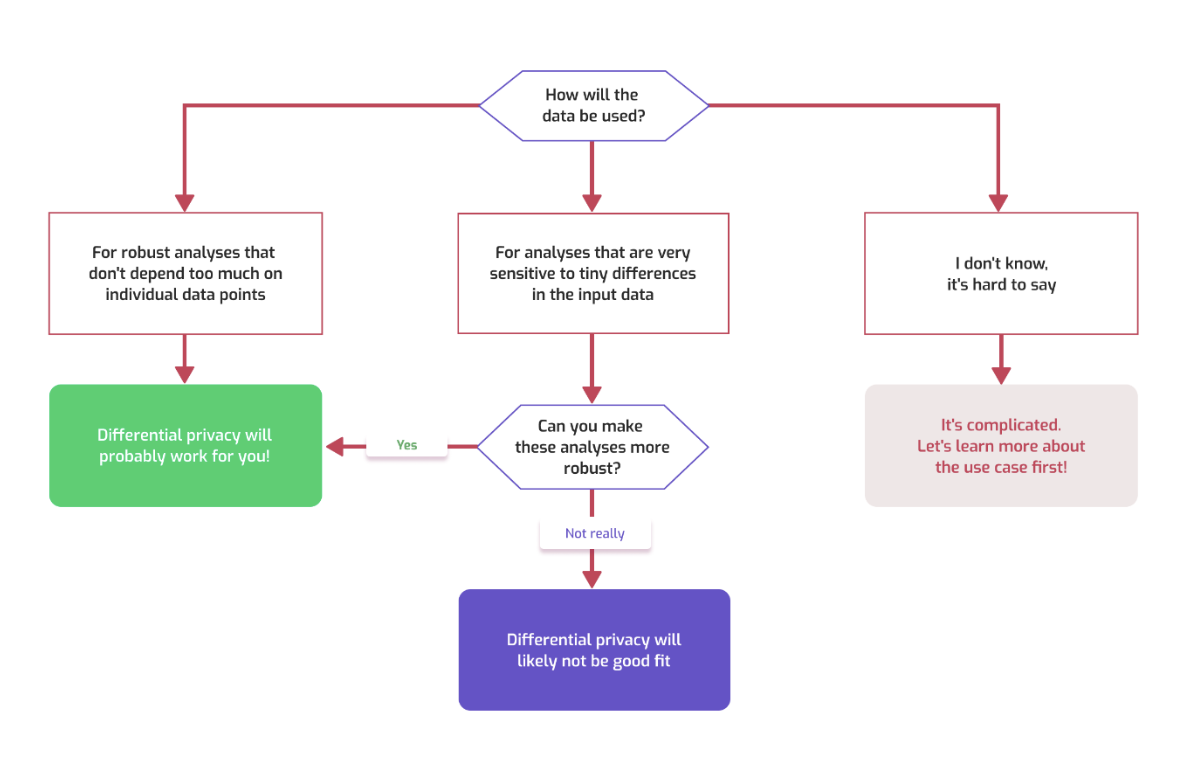
The value that DP can create is highly contextual – it will depend on the problem, the intended application, and the balance of trade-offs that can be tolerated by various stakeholders concerned. A “litmus test” for the applicability involves consideration of the intended application(s), their sensitivity to small variations in the input dataset, and the ability to create more “robust” versions of these applications where necessary. There is no “one size fits all” approach we can follow to applying and releasing differentially private data.
As we continue to develop into an “information society” whose systems are underpinned and facilitated by advanced data-based technologies, it is imperative that we mindfully identify and evaluate these and other trade-offs incurred. The quest to create a thriving digital economy, based on efficient and transparent governance, and advancing on a flourishing, sustainable development pathway, will involve a critical negotiation of privacy concerns at every step involving data.
The India Urban Data Exchange (IUDX), the facilitating data exchange platform of the National Smart Cities Mission, has a mission to “unleash the power of data for public good”. IUDX, in partnership with leading researchers in the field, is evaluating Differential Privacy-based approaches across a range of use-cases – including de-identification, computer vision and machine learning – which, in conjunction with other approaches, will find broad applicability in the Indian Smart Cities to problems in transport, energy and water management, citizen security, government planning, and more. Further articles in this series will explore some of this on-going work and its applicability in detail.
Author:
Hari Dilip Kumar
Related Posts





























{kind=link}